昨天發現程式處理完的結果跟我們設想的不太一樣,所以今天讓我們針對以下兩點來微調吧!
經過思考後,決定統一成小寫,之所以不採用大寫的理由是:
常數(constant),而非一個容易變動的值讓我們針對 processSplittedStr 中的段落進行調整:
if (!!weekday) {
// 統一成全部小寫
const formattedWeekday = weekday.toLowerCase();
temp.push(formattedWeekday);
splittedStrArr = splittedStrArr.filter((element) => element !== weekday);
} else {
exceptions.push(cloneSplittedStrArr);
return;
}
這邊可以看到把原先傳入 temp 的值 weekday,先經過一層小寫的轉換後,命名為 formattedWeekday 後,再傳入 temp 裡。
為什麼要重新 assign 一個變數呢?原因在於這樣比較好 debug。
如果今天我們採用這樣的寫法:
temp.push(weekday.toLowerCase());
這段 code 不僅比較難讀,而且也只會在 push 後才能透過 temp 的值改變,來觀察到底存了什麼進去,因而讓 debug 的工作變得困難。
決定統一移除斜線,並用人力統一轉換成 4 位數,理由是:
特殊字元(例如可以用作四則運算的除或是 regular expression 的開始與結尾),故除非必要否則不希望他存在於字串中31 的值225 以及 3/4 中間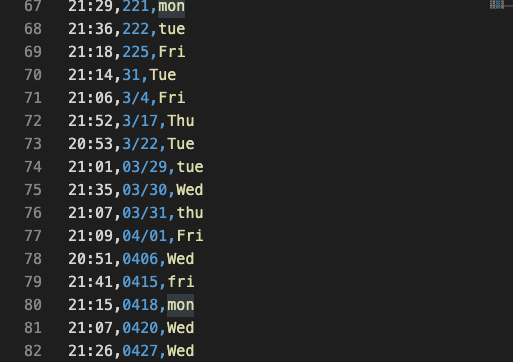
讓我們回到 processSplittedStr 中的段落進行調整:
if (!!date) {
// 移除字串中的斜線
const formattedDate = date.replace('/', '');
temp.push(formattedDate);
splittedStrArr = splittedStrArr.filter((element) => element !== date);
} else {
exceptions.push(cloneSplittedStrArr);
return;
}
這邊為什麼要額外 assign 一個變數出來的理由同前,就不再贅述。
讓我們重新執行一次 dayTimeStructurize.js,並且複製一份產出的 csv 檔,重新命名為 annoyance_output_manual.csv 來透過人力處理吧。
讀者們可能會經由這次的調整發現,一開始的資料結構(schema)先訂好,之後再來記錄會是比較妥當的做法。
筆者也是經由一陣子的記錄後,才對於最終資料要長什麼樣子有比較清楚的想像。
所以如果大家也想要開始一個專案的話,如果一開始有 schema 是最好的。但如果沒有也沒關係,因為記錄到後來就會知道,資料應該長什麼樣子,對於後續的利用是比較有幫助的。
結構化的部分今天可以告一段落了,讓我們收工!

